
Dynamic Bernoulli Embeddings (D-EMB), discussed here, are a way to train word embeddings that smoothly change with time. After finding the the paper authors’ code a bit challenging to use, I decided to create my own implementation. This post walks through that process and showcases some results of training the model on the UN General Debate corpus.
Motivation
I previously wrote about using Dynamic Topic Models to model the evolution of topics in the UN General Debate corpus. This analysis produced some interesting results that gave a nice overview of how persistent topics of global interest have changed over time. For example, the model captured the evolution on discussion about Africa from the end of colonialism, to apartheid, and now most recently to democracy and elections.
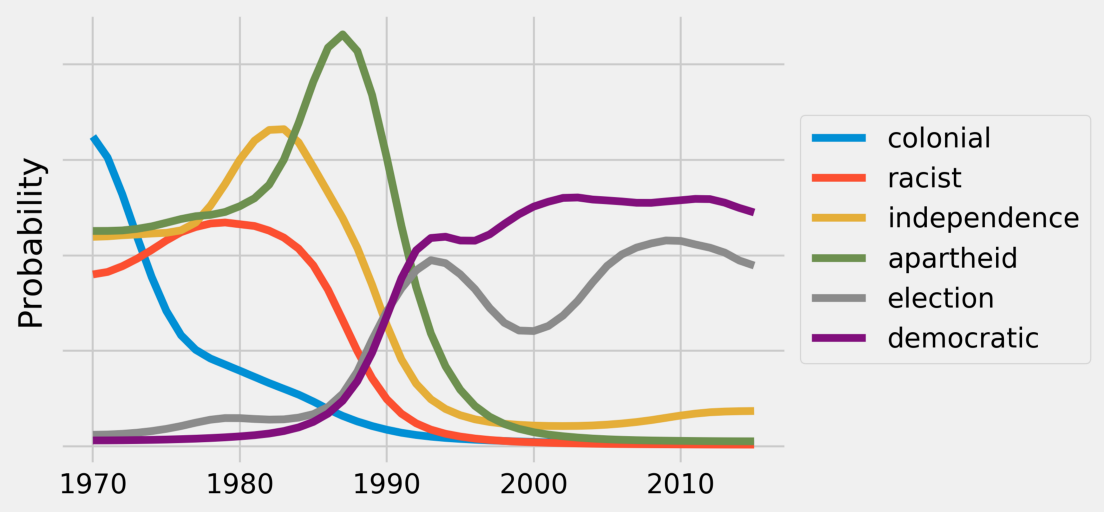
I have been interested in this idea of modelling the change of topics and language over time, so I wanted to take this analysis a bit further. Specifically, any kind of topic model forces you to work with the high level topics that the model discovers, but I wanted to be able to slice the data at a more granular level with questions like:
- What terms have changed the most over time?
- For a specific topic like “Syria”, can I chart it’s evolution through the years?
Deciding on the D-EMB Model
There has been some research into the idea of word embeddings that evolve over time, such as Temporal Analysis of Language Through Neural Language Models and Diachronic Word Embeddings Reveal Statistical Laws of Semantic Change. The former basically trains a Word2Vec model on each timestep, using as initial values the embeddings learned from the previous timestep. The latter builds on this idea slightly by adding an alignment step between the embeddings at different timesteps. The rationale for that is that Word2Vec can result in arbitrary orthogonal transformations that preserve meaningful cosine distance relationships between words in the same timestep but potentially confound any meaningful comparison across timesteps.
After trying this approach and seeing subpar results, I turned to Dynamic Embeddings for Language Evolution, the focus of this post. The authors of this paper have two main critiques for the above approaches. First, they require a lot of data for each timestep to train high quality embeddings (not the case in the UNGD corpus), and second, the necessity of having to do a weird post-training alignment step to make the dimensions of the embdedding comparable across timesteps is not ideal.
The Model
The model itself is quite simple with just two types of trainable parameters. The first is a separate embedding vector for each term in each timestep, and the second is a time independent context vector for each term.
Training the model is conceptually very similar to training Word2Vec using negative sampling with one addition that encodes a smooth temporal transition for embeddings. This comes in the form of a penalty term on the difference between embedding matrices at different timesteps.
Implementation Notes
-
The embeddings are represented in a single matrix, with timesteps stacked on top of each other. Specifically, we have a tensor of shape
(V * T, k)whereVis the vocabulary size,Tis the number of timesteps, andkis the dimension of the embedding. The firstVrows correspond to the embeddings from the first timestep, the secondVto the embeddings from the second timestep, etc. -
The implementation effectively concatenates all texts from a given timestep into one, treating it as a continuous stream of words. The impact of this is that the context for a target word at the very end of a text may include a few words from the beginning of some other unrelated text (within the same timestep). This is no problem if your texts are long, but it may be a problem with shorter texts. I may build in support for respecting such boundaries in the future.
-
The range of values for the scaling factor on the random walk prior ($\lambda = [1, 10]$) that the paper cites are an order of magnitude different than what the defaults in the authors’ code suggests. I think this suggested range is supposed to refer $\lambda_0 = [1, 10]$ where $\lambda = 1000 * \lambda_0$ as this is more in line with the defaults in the code and what ended up working for me.
-
The first epoch is used for initialization of the embeddings. To do this, I treat everything in the first epoch as coming from the first timestep and ignore the random walk prior term in the loss. When the epoch is finished, I initialize the embeddings for every timestep with those of the first timestep. The authors of the paper suggested a similar approach.
-
10% of the documents are held out for validation by default. The only metric computed on the validation set is the $L_{pos}$ value, which is basically how good the model is at predicting the target word given the context. No negative samples are drawn for the validation set.
Results on the General Debate Corpus
Training
There are multiple components to the loss function that we’re minimizing, and the overall loss is a weighted combination of these.
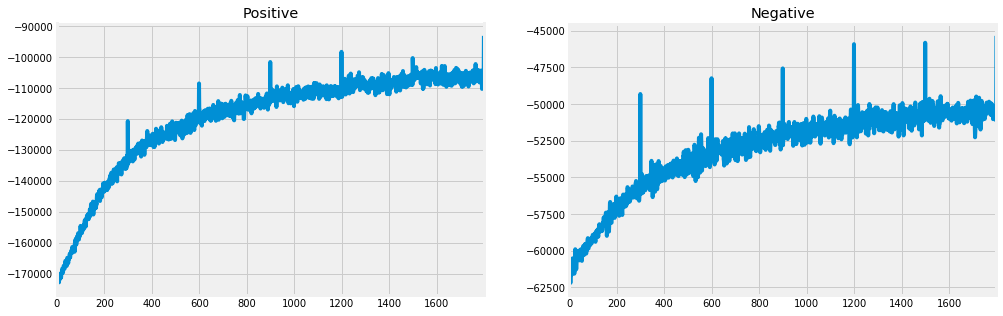
- Positive: How good is the model at positively predicting the target word from the context?
- Negative: How good is the model at negatively predicting the negative samples from the context?
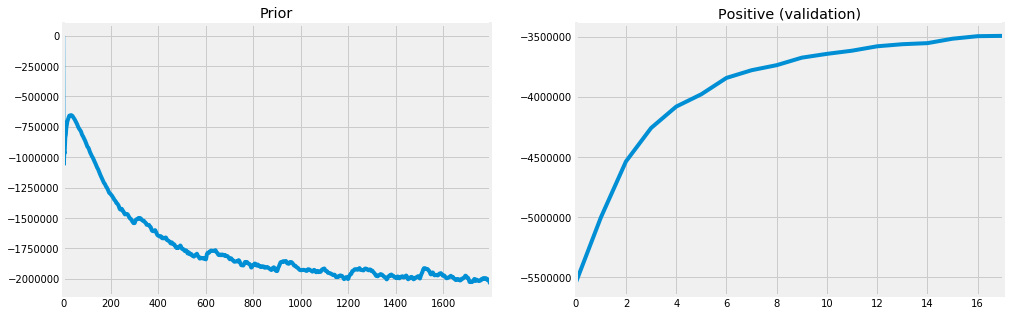
- Prior: How far are the embeddings drifting between timesteps?
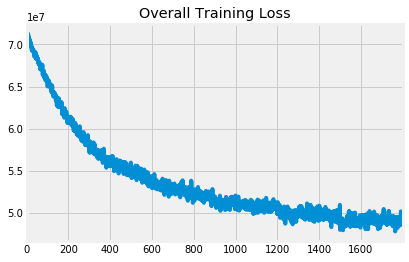
Let’s look at how this decomposes. These three components all have their signs flipped when contributing to the loss, so we hope to see them increasing. The positive and negative curves both do so nicely, while the prior curve is decreasing. This means that the prior term is contributing more and more to the loss over time, despite the loss decreasing. Intuitively though, this makes sense because we want the embeddings to drift, just not too far. Thus, getting the scaling factor correct on this term is crucial to ensure quality embeddings within timesteps and meaningful comparisons across timesteps.
Note the dips at the end of each epoch in the positive and negative curves. These are a consequence of the last batch being slightly smaller. They are normalized before contributing to the overall loss which is why the overall loss curve has no unusual behavior at the end of each epoch.
Finally, we can look at the positive component on the validation set to ensure that the model is generalizing.
Analysis
We can use the trained embeddings to do some cool analysis such as:
- finding which embeddings changed the most over time (absolute drift)
- looking for change points where an embedding significantly changed from one timestep to the next indicating some significant event
- looking up the nearest neighbors of an embedding and seeing how this “neighborhood” has changed over time
Let’s start by looking at absolute drift, which is the euclidean distance between the embeddings of each term at the first and last timesteps. Terms that drifted the most indicate that their usage has shifted.
Climate comes out on top, and European and Union appear which makes sense given the founding of the EU only in 1993 (and subsequent frequent usage of European and Union together). Millenium and Sustainable likely have to do in part with the advent of the Millenium and Sustainable Development Goals initiatives, and countries/regions that have seen significant change such as Syria and Africa also appear near the top.
| Term | Drift | |
|---|---|---|
| 0 | climate | 1.241559 |
| 1 | union | 1.221671 |
| 2 | south | 1.136769 |
| 3 | co | 0.985926 |
| 4 | agenda | 0.983631 |
| 5 | change | 0.951607 |
| 6 | post | 0.912055 |
| 7 | european | 0.889426 |
| 8 | southern | 0.888166 |
| 9 | twenty | 0.878703 |
| 10 | millennium | 0.869878 |
| 11 | sea | 0.865753 |
| 12 | africa | 0.851388 |
| 13 | serbia | 0.823497 |
| 14 | african | 0.774140 |
| 15 | sustainable | 0.770657 |
| 16 | summit | 0.762487 |
| 17 | north | 0.756751 |
| 18 | rule | 0.756369 |
| 19 | syria | 0.752415 |
We can take this idea of measuring embedding drift further by finding the term/timestep pairs corresponding to the largest single timestep changes. I call these “change points”, and they correlate with significant real world events. For example, the Arab Spring begain in Tunisia in 2010 and Iranian appears twice in consecutive years in this list after details of the Iran-Contra Affair emerged.
| Year | Term | Change | |
|---|---|---|---|
| 0 | 1993 | ukraine | 0.257642 |
| 1 | 2010 | tunisia | 0.232226 |
| 2 | 2014 | japan | 0.231548 |
| 3 | 1987 | iranian | 0.226282 |
| 4 | 1986 | iranian | 0.218671 |
| 5 | 1985 | rwanda | 0.207307 |
| 6 | 1993 | lebanon | 0.201297 |
| 7 | 2000 | sudan | 0.201279 |
| 8 | 1985 | italy | 0.201008 |
| 9 | 1999 | sudan | 0.200704 |
Finally, we can look at a term’s neighborhood in the embedding space across time. Let’s look at climate since it was found to have changed the most.
| 1970 | 1975 | 1980 | 1985 | 1990 | 1995 | 2000 | 2005 | 2010 | 2015 | |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | atmosphere | atmosphere | atmosphere | atmosphere | atmosphere | atmosphere | winds | winds | winds | climatic |
| 1 | détente | equilibrium | relaxation | relaxation | dynamics | winds | radical | radical | radical | ipcc |
| 2 | equilibrium | détente | détente | détente | winds | climatic | climatic | climatic | climatic | winds |
| 3 | dynamics | dynamics | equilibrium | equilibrium | détente | radical | atmosphere | ipcc | ipcc | radical |
| 4 | relaxation | relaxation | dynamics | realms | momentum | engendering | ipcc | impacts | resistant | bioenergy |
Conclusion
Like Dynamic Topic Models, dynamic word embeddings provide an interesting lens into how language usage changes over time. Applied to the UN General Debate corpus, we saw how they can tell us what terms are changing the most and point us directly to interesting change points that correlate with significant real world events.
The code is easy to use, pip installable, and located here. I hope it can be useful for others interested in similar exploratory analyses!